wsl üzerinde çalıştırdğınız bir uygulamaya ana makinenizin bağlı olduğu ağdan erişmek istiyorsanız , ip değişimlerinde her seferinde port erişim izinleri vb ile uğraşmak istemiyorsanız wsl in “mirrored networking” moduna geçirilmesi doğru bir tercih olabilir..
bunun için
C:\Users\kullanıcı_adi
dizini altında
.wslconfig
isimli bir dosya oluşturuyoruz ve
[wsl2]
networkingMode=mirrored
firewall=true
satırlarını ekliyoruz. bundan sonra değişikliklerin geçerli olması için wsl yeniden başlatmanız gerekmektedir.
nokia routerlar üzerinde aynı dakikalar içerisinde up/down olan portları bulmak için loglara bakmak en doğru yöntem olsada arayüzlerin last state change larından buna bakabiliriz. aşagıdaki basit komut işimize yarayacaktır.
A:router_a# environment no more
A:router_a# show port detail | match expression "02/26/2026 12:2|Interface"
Interface : esat-1/1/1 Oper Speed : 0 Mbps
Last State Change : 11/18/2025 01:20:11 Hold time down : 0 seconds
Interface : esat-1/1/2 Oper Speed : 1 Gbps
Last State Change : 02/26/2026 12:28:36 Hold time down : 0 seconds
Interface : esat-1/1/3 Oper Speed : 1 Gbps
Last State Change : 02/10/2026 04:16:28 Hold time down : 0 seconds
Interface : esat-1/1/4 Oper Speed : 1 Gbps
Last State Change : 02/26/2026 12:28:37 Hold time down : 0 seconds
Interface : esat-1/1/5 Oper Speed : 1 Gbps
Last State Change : 02/26/2026 12:28:38 Hold time down : 0 seconds
Interface : esat-1/1/6 Oper Speed : 1 Gbps
Last State Change : 02/26/2026 12:28:37 Hold time down : 0 seconds
Interface : esat-1/1/7 Oper Speed : 1 Gbps
Last State Change : 02/26/2026 12:28:37 Hold time down : 0 seconds
Interface : esat-1/1/8 Oper Speed : 1 Gbps
Last State Change : 02/26/2026 12:28:36 Hold time down : 0 seconds
nokia routerlarda toplu olarak sdp oluşturma ihtiyacı olurşursa aşağıdaki formatta bir excel dosyası oluşturup
sdpid
routera
routerb
routerbip
10093
router_a
routerb_b
10.10.10.1
4806
router_a
routerb_d
10.10.10.3
1078
router_a
routerb_f
10.10.10.5
aşagıdaki python kodu kullanarak oluşturduğumuz jinja formatına uygun kodları üretebiliriz… oluşturulacak routerda sdpid nin var olmaması gerekmektedir.
import pandas as pd
from jinja2 import Environment, FileSystemLoader
# Excel dosyasını oku
df = pd.read_excel('sdp_create.xlsx')
# Jinja2 ortamını ayarla (şablon dosyası ile aynı dizinde çalıştığını varsayıyoruz)
env = Environment(loader=FileSystemLoader('.'))
template = env.get_template('sdp_create_template.j2')
# Excel'den okunan veriyi listeye çevir
data = df.to_dict(orient='records')
# Jinja2 ile konfigürasyon dosyasını oluştur
output = template.render(items=data)
# Sonucu dosyaya yaz
with open('sdp_create_config.txt', 'w', encoding='utf-8') as f:
f.write(output)
sdp_create_template.j2 dosyasında sdp mpls olarak oluşturulup ldp yi aktif ettiğimiz bir örnek var.
{% for item in items %}
/configure service sdp {{ item.sdpid }} mpls create
info
description "to_{{ item.routerb }} "
far-end {{ item.routerbip }}
ldp
path-mtu 2000
keep-alive
shutdown
exit
no shutdown
{% endfor %}
NDT, Measurement Lab (M‑Lab) tarafından geliştirilen açık kaynaklı bir ağ performans testi aracıdır; upload, download ve gecikme gibi parametreleri ölçer M‑Lab NDT verileri açık şekilde Google Cloud Storage ve BigQuery üzerinden erişilebilir hâldedir.. Kullanılan M-Lab’in https://speed.measurementlab.net adresinden test yapabilmektedir.
Test sonuçlarının Türkiye verilerini incelemek amacıyla Google Cloud Console üzerinden veri çekmeye yönelik bir kod geliştirme ihtiyacı doğmuştur. Mevcut yöntemlerle veri alımı mümkün olsa da, Türkiye’de M-Lab servisi yaygın olarak kullanılmadığı için elde edilen veri setleri sınırlı ve temsil edici olmamaktadır.
nokia routerda belirli bir servis altındaki sapları silme ihtiyacı durumunda aşagıdaki kod kulllanılabilir.
import pandas as pd
from jinja2 import Environment, FileSystemLoader
# Excel dosyasını oku
df = pd.read_excel('sap_delete.xlsx')
# Jinja2 ortamını ayarla (şablon dosyası ile aynı dizinde çalıştığını varsayıyoruz)
env = Environment(loader=FileSystemLoader('.'))
template = env.get_template('sap_delete_template.j2')
# Excel'den okunan veriyi listeye çevir
data = df.to_dict(orient='records')
# Jinja2 ile konfigürasyon dosyasını oluştur
output = template.render(items=data)
# Sonucu dosyaya yaz
with open('sap_delete_config.txt', 'w', encoding='utf-8') as f:
f.write(output)
üretilecek komut için aşagıdaki jinja template ini kullanyoruz..
{% for item in items %}
/configure service vpls {{ item.SvcId }} sap {{ item.PortId }} shutdown
/configure service vpls {{ item.SvcId }} no sap {{ item.PortId }}
{% endfor %}
sap_delete_config.txt dosyasında tempalte sonucuna uygun konfigürasyon oluşmuş olacaktır..
kullanacağımız excel ise show service sap-using komutunun çıktısına uygun olarak aşagıdaki formatta olmaldıır..
PortId
SvcId
Ingress
Ing.
Egress
Egr.
Adm
Opr
lag-40:1011.0
1234
54
none
45
none
Up
Down
lag-42:1011.0
1234
54
none
45
none
Up
Down
lag-44:1011.0
1234
54
none
45
none
Up
Down
Gerekli kodları aşagdaıki github adresinden ulaşılabilir.
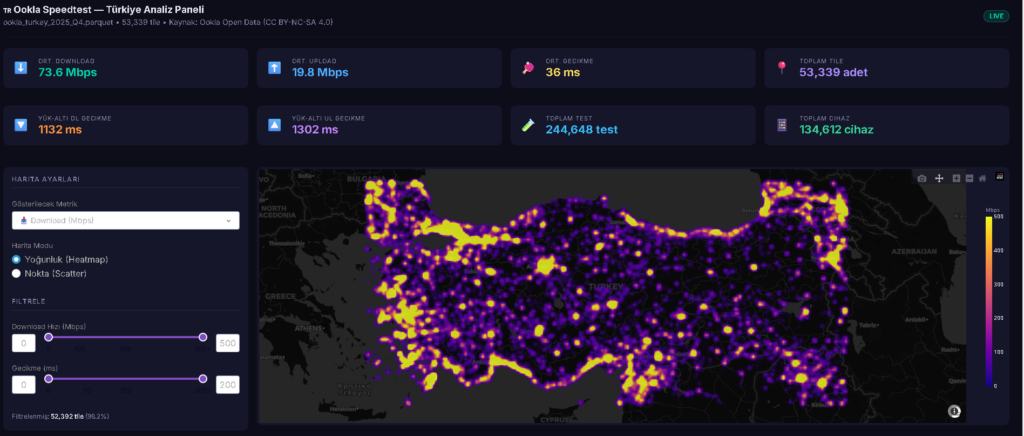
5g olaylarından dolayı hız testleri gündemde. bilinen ve doğru sonuç veren çok fazla hız testi sayfası yok. neredeyse hiç birinin açık verisi bulunmuyor. ookla nın çeyrek halinde yayınlandığı veriler bulunuyor ancak bu veriler çok kısıtlı.. örnek olarak operatör bilgisi bulunmuyor. bilr bölge için genel hız testi sonuçlarını incelemeye yardımcı olabiliryor.. açık veriler yılın çevrekleri şeklinde yayınlanıyor.
dosyalar belirli bir yapıya göre yayınlanıyor. en son yayınlanan çevrek verilerine göre türkiye verilerini indirecek bir python kod yazalım. verilerde doğrudan ülke bilgisi bulunmuyor. türkiyeyi içine alan koordinat bilgilerini kullanacağız. dikdörtgen şeklinde bir veri çekeceğimiz için sınırımızda diğer ülke verileride içinde yer alıyor.
ping sonucuna bakınca durumu daha net anlayacaksınız.
ping google.com
Pinging google.com [192.178.24.14] with 32 bytes of data:
Reply from 192.178.24.14: bytes=32 time=60ms TTL=112
Reply from 192.178.24.14: bytes=32 time=59ms TTL=112
Reply from 192.178.24.14: bytes=32 time=58ms TTL=112
Reply from 192.178.24.14: bytes=32 time=63ms TTL=112
Ping statistics for 192.178.24.14:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 58ms, Maximum = 63ms, Average = 60ms
ping -6 google.com
Pinging google.com [2a00:aaaa:aaaa:820::aaaa] with 32 bytes of data:
Reply from 2a00:aaaa:aaaa:820::aaaa: time=39ms
Reply from 2a00:aaaa:aaaa:820::aaaa: time=37ms
Reply from 2a00:aaaa:aaaa:820::aaaa: time=38ms
Reply from 2a00:aaaa:aaaa:820::aaaa: time=38ms
Ping statistics for 2a00:1450:4017:820::200e:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round trip times in milli-seconds:
Minimum = 37ms, Maximum = 39ms, Average = 38ms