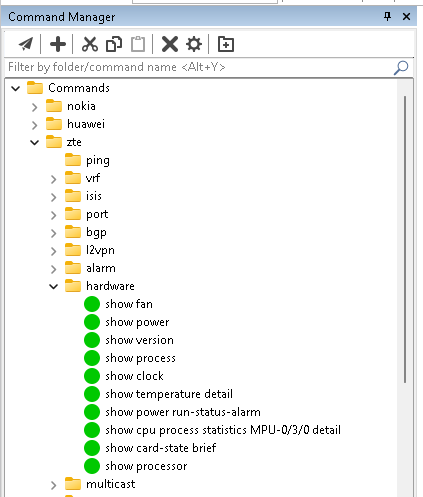
ağ yönetiminde ssh client uygulaması olarak securecrt oldukça popülerdir. eğer sizde securecrt kullanıyor ve kullanmayı planlıyorsanız network yönetimi sırasında commands manager aracı oldukça işinize yarayacaktır.
commands manager altıda istediğiniz komut tanımlamalarını yapabiliyor ve tek tıkla bu komutu aktif oturuma gönderebilirsiniz.. tasarım sırasında ağaç yapısı desteklemesi sayesinde kategorize edilmiş olarak komutları ekleyebilirsiniz…
tüm ihtiyacınız olabilecek komutları tek tek eklemez biraz yorucu olabilir.. bu noktada hazırladığım python scripti paylaşmacağım.. öncelikle ekleyeceğimiz komutları aşagıdaki formatta excel dosyasında hazırlıyoruz. vendor ve category olarak bir ağaç yapısı tasarladık.
commands.xlsx
Vendor
Category
Command
nokia
bgp
show router bgp summary
nokia
bgp
show router bgp neighbor
nokia
switch
show ethernet-service port 1/3
huawei
display ip interface brief
zte
show ip interface brief loopback0
xml_create.py
import pandas as pd
import xml.etree.ElementTree as ET
from xml.dom import minidom
def create_securecrt_xml(excel_file_path, output_xml_path):
# Excel dosyasını oku ve NaN değerleri boş string ile değiştir
df = pd.read_excel(excel_file_path).fillna("")
# Ana XML yapısını oluştur
root = ET.Element("VanDyke", version="3.0")
commands_root = ET.SubElement(root, "key", name="Commands")
# Vendor gruplarına göre işle
for vendor in df["Vendor"].unique():
if not vendor: # Vendor boşsa atla
continue
vendor_key = ET.SubElement(commands_root, "key", name=str(vendor))
# Kategoriye göre komutları grupla
vendor_data = df[df["Vendor"] == vendor]
for category in vendor_data["Category"].unique():
if pd.isna(category) or category == "": # Kategori boşsa genel komutlara ekle
continue
category_data = vendor_data[vendor_data["Category"] == category]
category_key = ET.SubElement(vendor_key, "key", name=str(category))
commands_key = ET.SubElement(category_key, "key", name="__Commands__")
default_array = ET.SubElement(commands_key, "array", name="Default")
# Komutları ekle
for _, row in category_data.iterrows():
if not row["Command"] or pd.isna(row["Command"]):
continue
command_str = f"SEND,{row['Command']},{row['Command']},,,0,1,{row['Command']},"
ET.SubElement(default_array, "string").text = command_str
# Vendor için genel komutlar (kategori yoksa)
general_commands = vendor_data[vendor_data["Category"].isna() | (vendor_data["Category"] == "")]
if not general_commands.empty:
commands_key = ET.SubElement(vendor_key, "key", name="__Commands__")
default_array = ET.SubElement(commands_key, "array", name="Default")
for _, row in general_commands.iterrows():
if not row["Command"] or pd.isna(row["Command"]):
continue
command_str = f"SEND,{row['Command']},{row['Command']},,,0,1,{row['Command']},"
ET.SubElement(default_array, "string").text = command_str
# XML'i düzgün formatla ve kaydet
xml_str = ET.tostring(root, encoding="utf-8")
dom = minidom.parseString(xml_str)
# toprettyxml encoding="utf-8" belirtilirse bytes döndürür, biz manuel yazıyoruz
body = dom.toprettyxml(indent="\t")
# toprettyxml'in ürettiği ilk satırı (<?xml ...?>) çıkar, yerine istediğimizin koy
lines = body.splitlines()
lines[0] = '<?xml version="1.0" encoding="UTF-8"?>'
# Boş satırları temizle (toprettyxml bazen ekstra boş satır ekler)
clean_lines = [l for l in lines if l.strip() != ""]
pretty_xml = "\n".join(clean_lines) + "\n"
with open(output_xml_path, "w", encoding="utf-8") as f:
f.write(pretty_xml)
if __name__ == "__main__":
excel_file_path = "commands.xlsx" # Excel dosyası yolu
output_xml_path = "securecrt_commands.xml" # Çıktı XML dosyası yolu
create_securecrt_xml(excel_file_path, output_xml_path)
print(f"XML dosyası oluşturuldu: {output_xml_path}")
excel ve python dosyasını ayını dizinde olacak şekilde çalıştırırsak aynı dizinde securecrt_commands.xml adından bir xml dosyası oluşturulacaktır.
excel olarak aldığımız bir rapor olduğunu varsayalım. bir sütundaki değerler tüm satırlarda aynı veriye sahipse bu sütun veri incelemede genelde gereksiz olabilir… bu şekilde çok fazla sütun varsa bunlardan kurtulmalmak için aşagdaıki bir kaç satırlık python kodunu kullanabiliriz.
NSP den aldığım örnek bir raporda 203 sutun mevcuttu. Bu kod sonrası 33 sutuna düşmüş oldu.
import pandas as pd
# Excel dosyasını oku
df = pd.read_excel("liste.xlsx")
# Tüm satırlarda aynı olan sütunları bul ve sil
df = df.loc[:, df.nunique() > 1]
# Sonucu kaydet
df.to_excel("liste_temiz.xlsx", index=False)
burada dikkat edilmesi gereken nokta listedeki tüm videoların aktif olmasıdır. kodda hata denetimi yapmadığımız için herhangi bir video silindiyse kod o noktada kesilecektir.
bir çoğumuzun hayatından artık mp3 dosyaları çıktı. artık sevidğimiz müzikleri ya online dinliyoruz yada tercih ettiğimiz bir uygulamanın offline modunu kullanıyoruz.
benim gibi bir kaç mp3 indirmek isteyen çıkabilir.
bunun için reklamlarla dolu video dosya içerisinden ses dosyasını kaydetmenize sağlayan bir sürü site var.. isterseniz bunlardan birini kullanabillirsiniz.. ama ben bunlarla uğraşmak istemediğim için basit bir uygulama yapmak istedim..
kodu tabiki pythonda yazacağız.. kod sırasında bize yardımcı olacak bir çok modül mevcut. bunların bir çoğu ffmpeg kullanıyor ve pc nizde kurulu olmasını şart koşuyor.
bu noktada yt_dlp yardımımıza yetişiyor. denediğim modüller arasında en sağlık çalışanı yt_dlp oldu.
şimdi adresini bildiğimiz bir youttube url için yt_dlp modulunu kullanarak mp3 dosyasını nasıl elde ederiz basit bir örnek yapalım.
temel kodumuz yukarıdaki gibi olacaktır… mp3 olarak indirmek istediğiniz bir video dosyasının idsini koddaki <video_id> ile değiştirir ve kodu çalıştırsanız aşagıdaki gibi çıktı ile çarşılacaksınız.
[youtube] Extracting URL: https://www.youtube.com/watch?v=8umGN3KiGY4
[youtube] 8umGN3KiGY4: Downloading webpage
[youtube] 8umGN3KiGY4: Downloading tv client config
[youtube] 8umGN3KiGY4: Downloading player e7567ecf
[youtube] 8umGN3KiGY4: Downloading tv player API JSON
[youtube] 8umGN3KiGY4: Downloading ios player API JSON
[youtube] 8umGN3KiGY4: Downloading m3u8 information
[info] 8umGN3KiGY4: Downloading 1 format(s): 251
[download] Destination: mp3_klasor\Passenger - Let Her Go.webm
[download] 100% of 4.05MiB in 00:00:00 at 8.79MiB/s
[ExtractAudio] Destination: mp3_klasor\Passenger - Let Her Go.mp3
Deleting original file mp3_klasor\Passenger - Let Her Go.webm (pass -k to keep)
uzaktan kontrol ve zamanlama için bir adet akıllı priz ihtiyacı oldu. bir alış veriş sitesinden kampanyadan faydalanarak günsan elektrik e ait olan prizden sipariş verdim. ürünün resmi sayfası
yerli ürün alalım diye düşürken içten içe üzerine günsan yazılmış fason olarak üretilmiş bir ürün alaağımı biliyordum. günsan smart life uygulamasını kendisine göre uyarlamış ama eksiklerde kalmış.. bazı yerlerde hala smartlife yazıyor 🙂
günsanın gg smart isimli uygulamasını kullanarak kısa sürede ürünü uygulamaya sorunsuz olarak ekleyebiliyorsunuz. tuya veya smart life uygulamasını kullanmak istersenizde sorun yaşamıyorsunuz.
buraya kadar sorun yok ancak sizde benim gibi uygulamalarda istediğinizi yapamıyorsanız, verilerinizi dış dünya ile paylaşmak istemiyor ve olası güvenlik açıklarının önüne geçmek istiyebilirsiniz.
bunun için kendi uygulamamızı yazabiliriz veya evinizde çalıştırdığınız bir akıllı ev asistanına ekleyebilirsiniz. ancak bunu yapabilmeniz için cihazın iletşim prokolu vb bilgileri gerekli. bu bilgiler ne yazıkkı cihaz ile doğrudan size gelmiyor.
adım adım bu bilgileri nasıl elde edeceğimize ve nasıl basit bir program yazacağımıza bakalım.
öncelikle akıllı prizinize smart life uygulamasına doğru şekilde ekleyin.
akıllı priz wifi desteğine sahip olduğu için ipsini öğrenmeliyiz. bunu ağınızda ip taraması veya modem arayüzünden rahatlıkla bulabilirsiniz. sonrasına bir port scanner ile açık olan portları bulmalıyız… bu ürün 6666, 6667, 6668 portlarını kullanıyor.
ihtiyacımız olan diğer bilgilere ulaşmanın bir kaç yöntemi var.
en temel haliyle yakadığımız pakeleri analiz ederek bu verilere ulaşabiliriz.. mitm, proy , wireshak vb ile uğraşmayı seviyersanız konuya zaten hekimsinizdir burada anlatmayacağım, siz hallederseniz. biz daha basit olan yöntemlere bakalım.
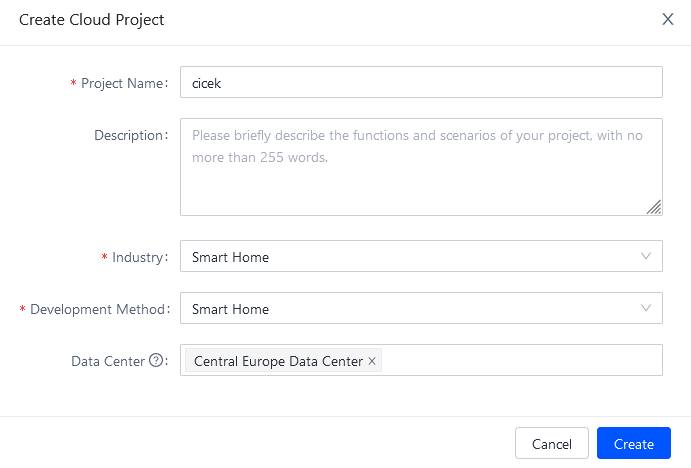
tuya geliştirici ortamı üzerinden nasıl öğreneceğimizi inceleyelim. öncelikle
adresinden bir proje oluşturalım.. proje oluştururken aşagıdaki parametreleri kullanabilirsiniz. dikkat etmeniz gereken nokta data center seçimi olacak. ileleyen aşamalarda yapacağımız bazı işlemlerde seçtiğiniz data center önem kazanıyor.. US veya Central Europe seçmenizi öneririm..
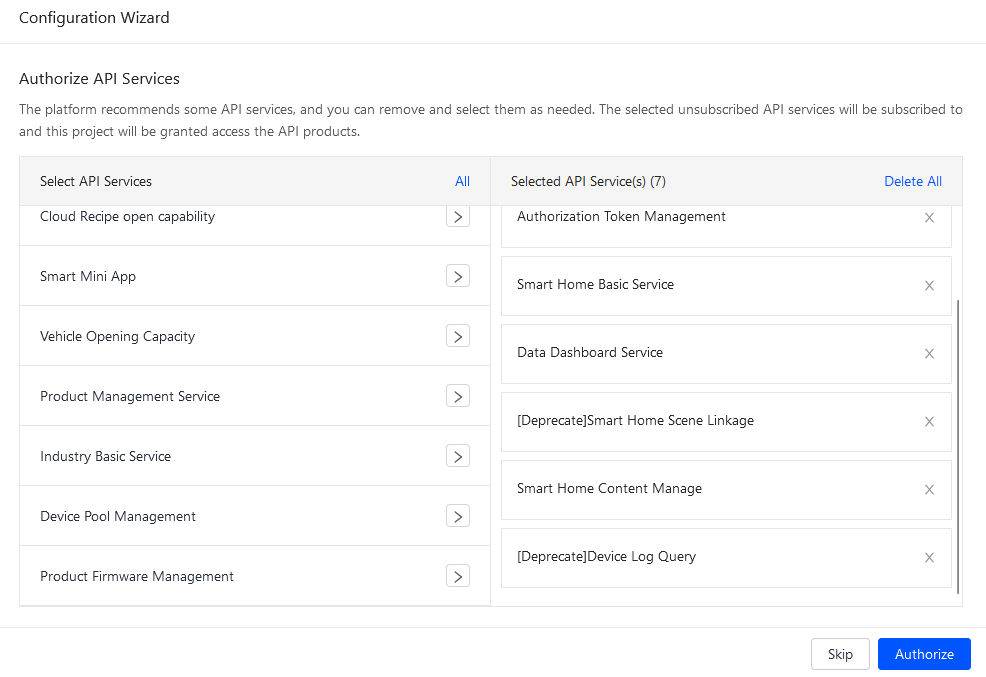
sonrasında kullanacağınız api servislerini belirlemeniz gerekiyor. Smart Home Content Manage, [Deprecate]Device Log Query , Smart Home Basic Service, [Deprecate]Smart Home Scene Linkage servislerinin seçili olması olmasına dikkat edelim.
projeyi oluşturduktan sonra aşagıdaki gibi ekran bizi karşılayacaktır.
Device altına giriyoruz
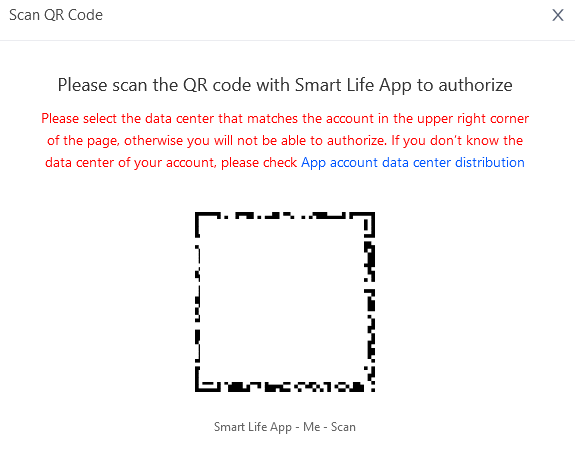
sonrasında Link App Account a seçip Add App Account butonuna tıklıyoruz. açılan penceredki qr kodu
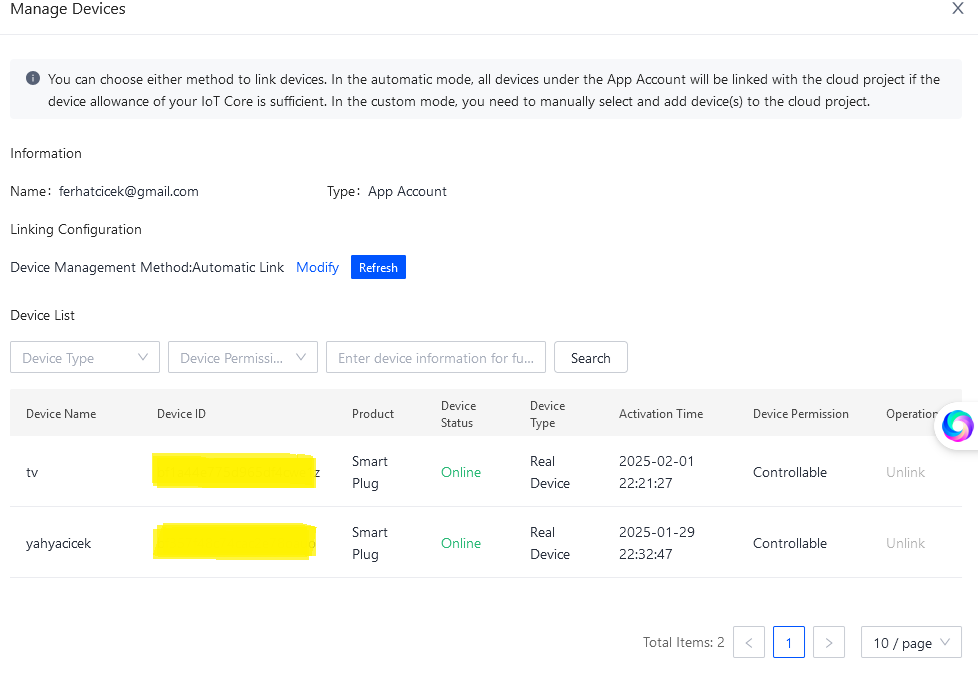
smart life uygulamasında tanımlama kısmında taratacağız. bu işlem başarılı olarak tamamlandıktan sonra smart life uygulamasına eklediğiniz tuya destekli cihazları platformda görmeye başlayacaksınız
Device Permission ayarlarını Controllable olarak ayarlayın.. buraya kadar yaptıklarımız sayesinde tuya developer üzerinden akıllı prizlerimizi kontrol edebilir ve izleyebilir duruma getirmiş olduk.
kilo almaya başlayınca vücut kütle endeksini ögreniyorsunuz.
vke = kilo / boy^2
şeklinde bir formülü varmış. boy metre cinsinden olmalı.. bunu ögrendiğimize göre oturduğumuz yerden beynimizde ve parmaklarımızda bir miktar kalori yakalım.
bu formül için bir api yapalım… api GET ile yapılan isteğe json dönüşü yapsın. bunu python – flask kullanarak gerçekleştirelim.
from flask import Flask, request, jsonify
app = Flask(__name__)
# Vücut Kitle Endeksi Hesaplama Fonksiyonu
def hesapla_vke(kilo, boy):
try:
# Boy metre cinsinden olmalı, örneğin: 1.75 m
vke = kilo / (boy ** 2)
return vke
except ZeroDivisionError:
return "Boy 0 olamaz!"
except Exception as e:
return str(e)
# VKE Kategorisini Belirleyen Fonksiyon
def vke_kategorisi(vke):
if vke < 18.5:
return "Zayıf"
elif 18.5 <= vke < 24.9:
return "Normal"
elif 25 <= vke < 29.9:
return "Fazla Kilolu"
else:
return "Obez"
# VKE Hesaplamak
@app.route('/hesapla_vke', methods=['GET'])
def hesapla():
# URL parametreleri ile kilo ve boy alıyoruz
kilo = request.args.get('kilo', type=float)
boy = request.args.get('boy', type=float)
# Kilo ve boy parametrelerinin kontrolü
if kilo is None or boy is None:
return jsonify({"error": "Lütfen 'kilo' ve 'boy' parametrelerini giriniz!"}), 400
# VKE'yi hesaplayalım
vke = hesapla_vke(kilo, boy)
if isinstance(vke, str): # Eğer hata mesajı döndüyse
return jsonify({"error": vke}), 400
# Kategoriyi belirleyelim
kategori = vke_kategorisi(vke)
# Sonucu JSON formatında döndürelim
return jsonify({
"kilo": kilo,
"boy": boy,
"vke": vke,
"kategori": kategori
})
if __name__ == '__main__':
app.run(debug=True, port=5000)
ortalama değer bir veri kümesindeki sayıların toplamının eleman sayısına bölümü olarak hesaplanır.
bunu yapacak bir fonksiyon yazalım.
def ortalama_bul(veri_kumesi):
toplam = sum(veri_kumesi)
eleman_sayisi = len(veri_kumesi)
ortalama = toplam / eleman_sayisi
return ortalama
bu yöntem düşük boyutlu veri kümeleri ile çalışırken yeterli olacaktır ancak veri kümesi büyüdükçe dahah hızlı bir yöntem gerekecektir. bu durumu yapacağımız örnekle inceleyelim.
numpy ile belirli boyutta bir veri kümeisi oluşturalım. yazdığımız fonkisyon ve alternatif olarak numpy nin mean metodu ile ortalama değeri hesaplamasını yapabilecek bir kod yazalım. hesaplamanın ne kadar sürede yapıldığını öğrenmek adına basit bir time yöntemi eklemeyi unutmayalım.
import numpy as np
import time
# Veri kümesinin ortalamasını bulan fonksiyon
def ortalama_bul(veri_kumesi):
toplam = sum(veri_kumesi)
eleman_sayisi = len(veri_kumesi)
ortalama = toplam / eleman_sayisi
return ortalama
# veri kümesi oluştur
veri_kumesi = np.random.rand(10000)
# numpy ile ortalama bulma
np_baslangic_zamani = time.time()
np_ortalama = np.mean(veri_kumesi)
np_bitis_zamani = time.time()
print(f"Numpy ile Ortalama hesaplama süresi: {np_bitis_zamani - np_baslangic_zamani} saniye")
print(f"Numpy ile Veri kümesinin ortalaması: {np_ortalama}")
# ortalama_bul fonksiyonunu kullanarak ortalama bulma
fonk_baslangic_zamani = time.time()
fonk_ortalama = ortalama_bul(veri_kumesi)
fonk_bitis_zamani = time.time()
print(f"Fonksiyon Ortalama hesaplama süresi: {fonk_bitis_zamani - fonk_baslangic_zamani} saniye")
print(f"Fonksiyon ile Veri kümesinin ortalaması: {fonk_ortalama}")
yukarıdaki kodda 10.000 adet veri için ortalama hesapları yapılmaktadır. kodu çalıştırdığımda elde ettiğim sonuç aşagıdaki gibidir.
Numpy ile Ortalama hesaplama süresi: 0.0 saniye
Numpy ile Veri kümesinin ortalaması: 0.5017341979294518
Fonksiyon Ortalama hesaplama süresi: 0.0 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.5017341979294502
veri boytunu katlayarak sonuçları kıyaslayalım. 100.000 değer için.
Numpy ile Ortalama hesaplama süresi: 0.0 saniye
Numpy ile Veri kümesinin ortalaması: 0.5008137222243555
Fonksiyon Ortalama hesaplama süresi: 0.0 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.5008137222243564
1.000.000 değer için
Numpy ile Ortalama hesaplama süresi: 0.0 saniye
Numpy ile Veri kümesinin ortalaması: 0.5000936635960163
Fonksiyon Ortalama hesaplama süresi: 0.046967267990112305 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.5000936635960234
hesaplamalarda ufak farklar görülmeye başladı. 10.000.000 için
Numpy ile Ortalama hesaplama süresi: 0.014102935791015625 saniye
Numpy ile Veri kümesinin ortalaması: 0.5002303952512933
Fonksiyon Ortalama hesaplama süresi: 0.5047390460968018 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.5002303952512889
aradaki fark artıyor. verimizi arttırmaya devam. 100.000.000 için
Numpy ile Ortalama hesaplama süresi: 0.09502911567687988 saniye
Numpy ile Veri kümesinin ortalaması: 0.49998983843975686
Fonksiyon Ortalama hesaplama süresi: 5.2369115352630615 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.4999898384397282
olarak bir çıktı elde ediyoruz. artık hesaplama süresini hissetmeye başladık. durmak yok veriyi büyütmeye devam
Traceback (most recent call last):
File "D:\python\ortalama.py", line 13, in <module>
veri_kumesi = np.random.rand(1000000000)
File "numpy\\random\\mtrand.pyx", line 1218, in numpy.random.mtrand.RandomState.rand
File "numpy\\random\\mtrand.pyx", line 436, in numpy.random.mtrand.RandomState.random_sample
File "_common.pyx", line 307, in numpy.random._common.double_fill
numpy.core._exceptions._ArrayMemoryError: Unable to allocate 7.45 GiB for an array with shape (1000000000,) and data type float64
1 Milyar için hesaplama yapmak istediğimde ise numpy için kırılma noktasına gelmiş olduğumuz görüyoruz. numpy ile devam etmek istiyorsak veri kümesini bölerek işlem yapmalıyız. buna uygun basit bir kod yazalım.
import numpy as np
import time
# Veri kümesinin boyutu ve parça boyutu
veri_boyutu = 1000000000
parca_boyutu = 100000
# Ortalamaları saklamak için bir liste oluştur
ortalama_listesi = []
np_baslangic_zamani = time.time()
# Veri kümesini parçalara böl ve her parçanın ortalamasını hesapla
for _ in range(veri_boyutu // parca_boyutu):
veri_kumesi = np.random.rand(parca_boyutu)
ortalama = np.mean(veri_kumesi)
ortalama_listesi.append(ortalama)
# Tüm parçaların ortalamasını hesapla
genel_ortalama = np.mean(ortalama_listesi)
np_bitis_zamani = time.time()
print(f"Veri kümesinin genel ortalaması: {genel_ortalama}")
print(f"Ortalama hesaplama süresi: {np_bitis_zamani - np_baslangic_zamani} saniye")
bu kod içinde parca_boyutu artııkça toplam hesaplama süresinin uzadığı görülmektedir.
işleri daha karmaşık hale getirmek istemiyorsak dask modulünü kullanmak farklı çözüm olacaktır.
import dask.array as da
import dask
import time
dask_baslangic_zamani = time.time()
# örnek veri kümesi oluştur
veri_kumesi = da.random.random(size=(1000000000,), chunks=1000000)
# Ortalama hesaplama
ortalama = da.mean(veri_kumesi)
# Dask hesaplamasını başlatma
with dask.config.set(scheduler='threads'):
sonuc = ortalama.compute()
dask_bitis_zamani = time.time()
# Hesaplanan ortalama değeri ekrana yazdırma
print(f"Veri kümesinin ortalaması: {sonuc}")
print(f"Dask ile Ortalama hesaplama süresi: {dask_bitis_zamani - dask_baslangic_zamani} saniye")
dask ile çalışırkenden chunks değeri hesaplama sürenizi eklieyecektir. 1 milyar değer için 100 bin değeri bende en optimal sonucu veriyor.
1 milyar veri için dask ve numpy de en optimal parametreler ile elde edilen sonuçlar aşagıdaki gibi çıkmakta…
dask
numpy
1 milyar veri
1 milyar veri
2.631504535675049 saniye
5.981382369995117 saniye
buradaki kodlar en optimal kodlar olmayabilir ve daha hızlı yöntemler oluşturulabilir. ancak bu haliyle kişisel bigisayarımda 1 milyar ve üzeri veriler için dask kullanmak çok daha mantıklı geliyor.
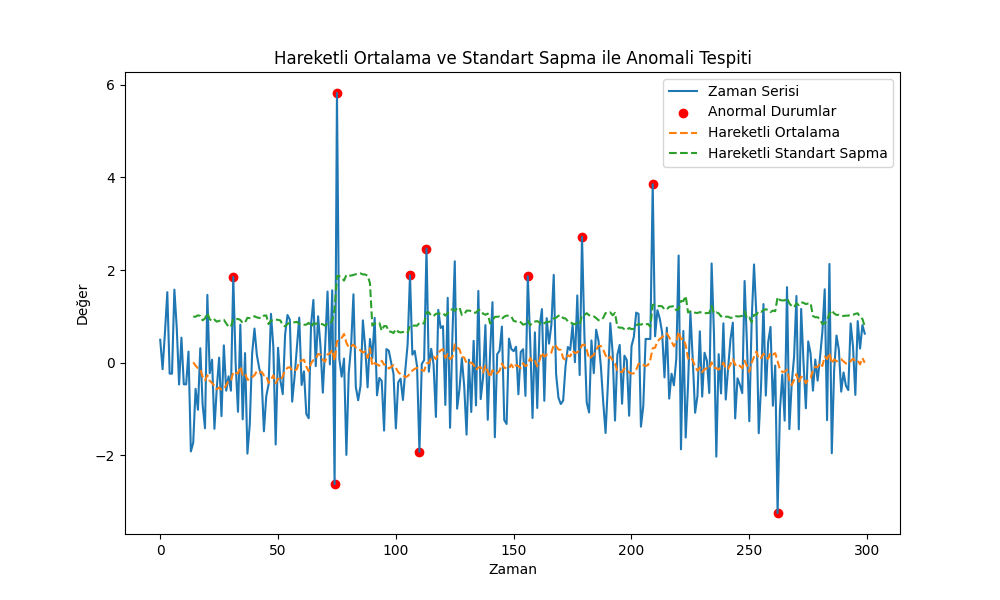
bir zaman serisinde anormal noktaların tespitinde kullanılabilecek yöntemlerden bir tanesi hareketli ortalama ve standart sapma kullanmaktadır. basit bir python uygulaması yapalım…
çıktıdan görüleceği gibi doğruluk oranı tüm uygulamalar için işe yaramayabilir. anomali tespiti giriş seviye uygulamalarda kullanılabilir.
pythonda çalışmanın dezavantajlarından bir tanesi yazdığınız kodları işletim sisteminde çalıştırabilir dosya haline getirme konusudur. çok fazla tercih etmesemde bazen gerekebiliyor.. bu noktada birden fazla seçenek mevcut ancak genel olarak en popüler olanları kullanmak daha fazla kütüphane v.b. konuda soun yaşamamanızı sağlıyor.
pyinstaller seçeneklerin en popüleri diye biliriz. tabiki ilk önce kurmamız gerekiyor.
pip install pyinstaller
kurulumu tamamladıktan sonra kullanımı oldukça kolay. komut yorumluyacısında ihtiyacımız olan parametreleri girerek exe dosyasını oluşturuyoruz.
pyinstaller --onefile dosyaadi.py
komut tamamlandığından python dosyasının bulunduğu klasör içine dist ve build isimli iki yeni klasör oluştuğunu göreceksiniz. dist klasöründen exe dosyanız build klasöründen ise exe oluşturma sürecinde kullanılan dosyalar yer almaktadır.
yukarıdaki komut yapısını kullandığınızda yazdığınız kod ihtiyaç duyulan tüm sistem dosyalarını tek bir dosya içine dahil etmektedir. bu nedenden dolayı dist klasöründeki exe dosyasına incelediğinizde yazdığımız üç beş satır koda karşı oldukça büyük boyutlu olduğunuz göreceksiniz.
eğer gui şeklinde bir uygulama yaptızsanız programı çalıştırdığınız ilave bir console pencesi açılmaması adına noconsole parametresinin eklenmesi gerekmektedir.
pyinstaller --onefile --noconsole dosyaadi.py
oluşturlan dosyanın iconunu değiştirme gibi bir çok seçenek için https://pyinstaller.org/ adresi incelemenizi öneririm.