nokia routerlarda toplu olarak sdp oluşturma ihtiyacı olurşursa aşağıdaki formatta bir excel dosyası oluşturup
sdpid
routera
routerb
routerbip
10093
router_a
routerb_b
10.10.10.1
4806
router_a
routerb_d
10.10.10.3
1078
router_a
routerb_f
10.10.10.5
aşagıdaki python kodu kullanarak oluşturduğumuz jinja formatına uygun kodları üretebiliriz… oluşturulacak routerda sdpid nin var olmaması gerekmektedir.
import pandas as pd
from jinja2 import Environment, FileSystemLoader
# Excel dosyasını oku
df = pd.read_excel('sdp_create.xlsx')
# Jinja2 ortamını ayarla (şablon dosyası ile aynı dizinde çalıştığını varsayıyoruz)
env = Environment(loader=FileSystemLoader('.'))
template = env.get_template('sdp_create_template.j2')
# Excel'den okunan veriyi listeye çevir
data = df.to_dict(orient='records')
# Jinja2 ile konfigürasyon dosyasını oluştur
output = template.render(items=data)
# Sonucu dosyaya yaz
with open('sdp_create_config.txt', 'w', encoding='utf-8') as f:
f.write(output)
sdp_create_template.j2 dosyasında sdp mpls olarak oluşturulup ldp yi aktif ettiğimiz bir örnek var.
{% for item in items %}
/configure service sdp {{ item.sdpid }} mpls create
info
description "to_{{ item.routerb }} "
far-end {{ item.routerbip }}
ldp
path-mtu 2000
keep-alive
shutdown
exit
no shutdown
{% endfor %}
NDT, Measurement Lab (M‑Lab) tarafından geliştirilen açık kaynaklı bir ağ performans testi aracıdır; upload, download ve gecikme gibi parametreleri ölçer M‑Lab NDT verileri açık şekilde Google Cloud Storage ve BigQuery üzerinden erişilebilir hâldedir.. Kullanılan M-Lab’in https://speed.measurementlab.net adresinden test yapabilmektedir.
Test sonuçlarının Türkiye verilerini incelemek amacıyla Google Cloud Console üzerinden veri çekmeye yönelik bir kod geliştirme ihtiyacı doğmuştur. Mevcut yöntemlerle veri alımı mümkün olsa da, Türkiye’de M-Lab servisi yaygın olarak kullanılmadığı için elde edilen veri setleri sınırlı ve temsil edici olmamaktadır.
nokia routerda belirli bir servis altındaki sapları silme ihtiyacı durumunda aşagıdaki kod kulllanılabilir.
import pandas as pd
from jinja2 import Environment, FileSystemLoader
# Excel dosyasını oku
df = pd.read_excel('sap_delete.xlsx')
# Jinja2 ortamını ayarla (şablon dosyası ile aynı dizinde çalıştığını varsayıyoruz)
env = Environment(loader=FileSystemLoader('.'))
template = env.get_template('sap_delete_template.j2')
# Excel'den okunan veriyi listeye çevir
data = df.to_dict(orient='records')
# Jinja2 ile konfigürasyon dosyasını oluştur
output = template.render(items=data)
# Sonucu dosyaya yaz
with open('sap_delete_config.txt', 'w', encoding='utf-8') as f:
f.write(output)
üretilecek komut için aşagıdaki jinja template ini kullanyoruz..
{% for item in items %}
/configure service vpls {{ item.SvcId }} sap {{ item.PortId }} shutdown
/configure service vpls {{ item.SvcId }} no sap {{ item.PortId }}
{% endfor %}
sap_delete_config.txt dosyasında tempalte sonucuna uygun konfigürasyon oluşmuş olacaktır..
kullanacağımız excel ise show service sap-using komutunun çıktısına uygun olarak aşagıdaki formatta olmaldıır..
PortId
SvcId
Ingress
Ing.
Egress
Egr.
Adm
Opr
lag-40:1011.0
1234
54
none
45
none
Up
Down
lag-42:1011.0
1234
54
none
45
none
Up
Down
lag-44:1011.0
1234
54
none
45
none
Up
Down
Gerekli kodları aşagdaıki github adresinden ulaşılabilir.
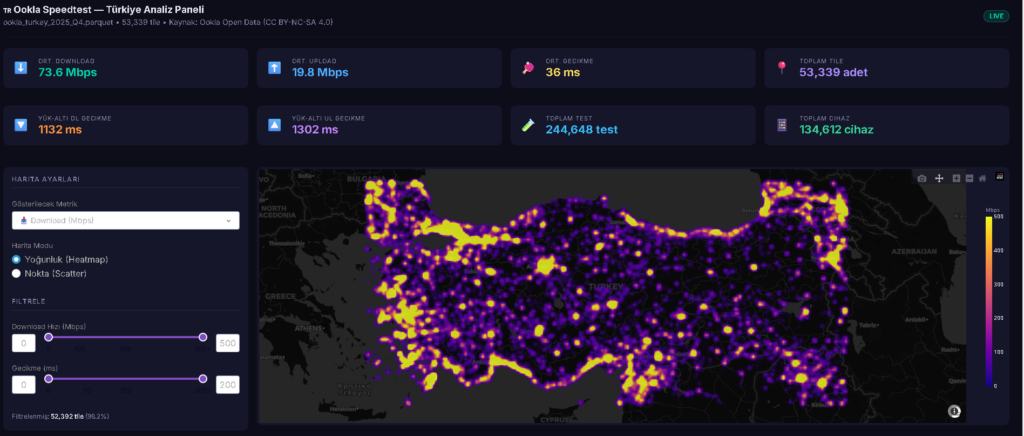
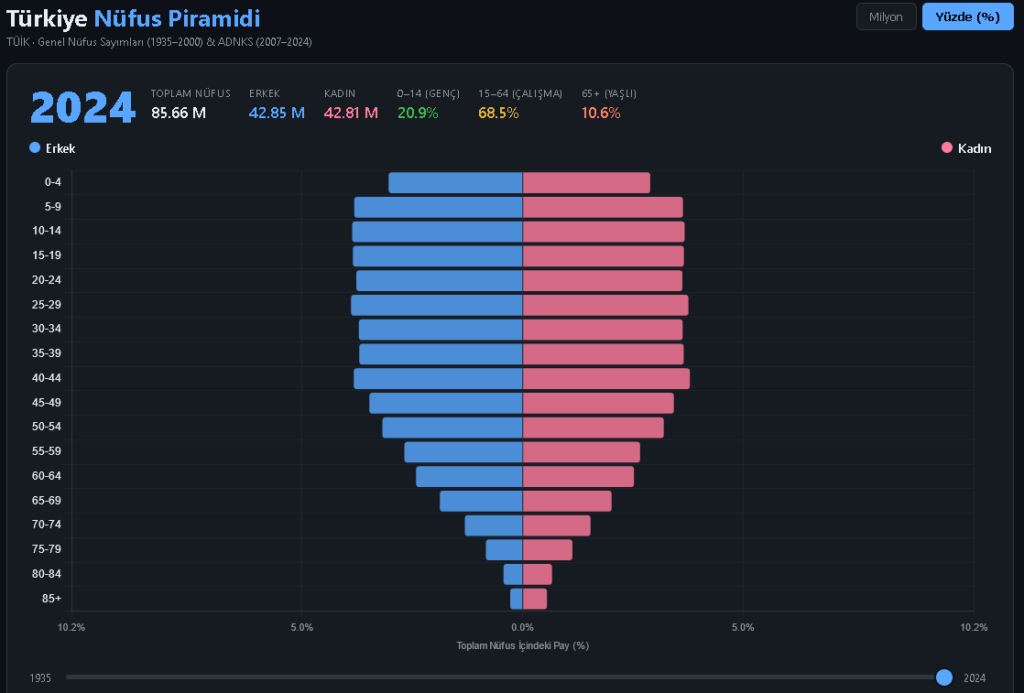
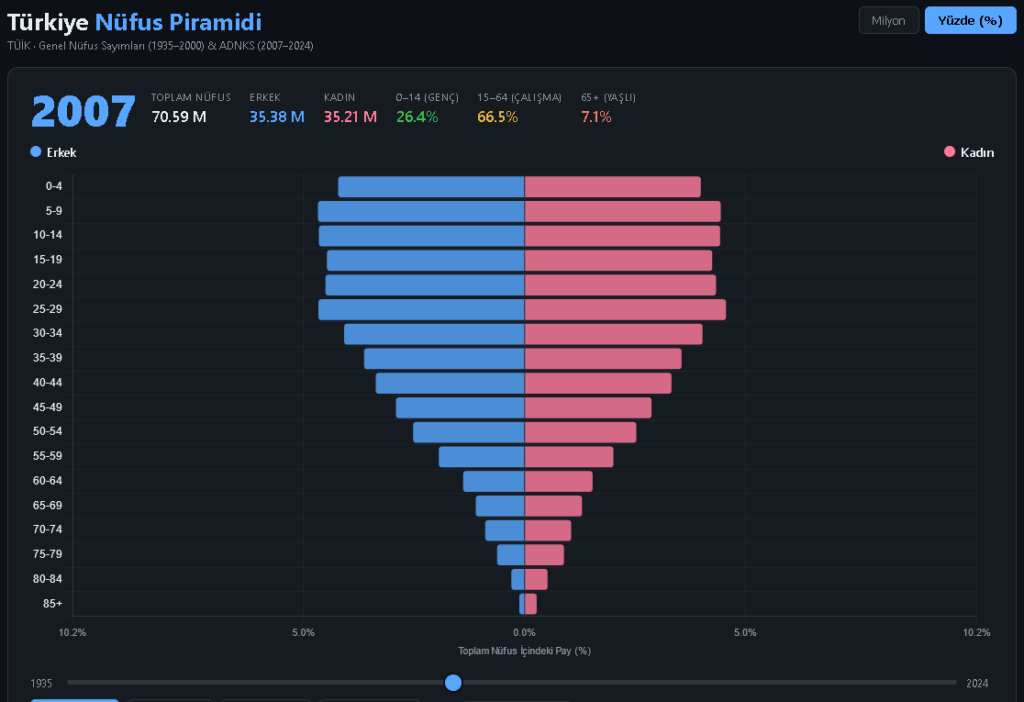
5g olaylarından dolayı hız testleri gündemde. bilinen ve doğru sonuç veren çok fazla hız testi sayfası yok. neredeyse hiç birinin açık verisi bulunmuyor. ookla nın çeyrek halinde sayılandığı veriler bulunuyor ancak bu veriler çok kısıylı.. örnek olarak operatör bilgisi bulunmuyor. bilr bölge için genel hız testi sonuçlarını incelemeye yardımcı olabiliryor.. açık veriler yılın çevrekleri şeklinde yayınlanıyor.
dosyalar belirli bir yapıya göre yayınlanıyor. en son yayınlanan çevrek verilerine göre türkiye verilerini indirecek bir python kod yazalım. verilerde doğrudan ülke bilgisi bulunmuyor. türkiyeyi içine alan koordinat bilgilerini kullanacağız. dikdörtgen şeklinde bir veri çekeceğimiz için sınırımızda diğer ülke verileride içinde yer alıyor.
ortalama değer bir veri kümesindeki sayıların toplamının eleman sayısına bölümü olarak hesaplanır.
bunu yapacak bir fonksiyon yazalım.
def ortalama_bul(veri_kumesi):
toplam = sum(veri_kumesi)
eleman_sayisi = len(veri_kumesi)
ortalama = toplam / eleman_sayisi
return ortalama
bu yöntem düşük boyutlu veri kümeleri ile çalışırken yeterli olacaktır ancak veri kümesi büyüdükçe dahah hızlı bir yöntem gerekecektir. bu durumu yapacağımız örnekle inceleyelim.
numpy ile belirli boyutta bir veri kümeisi oluşturalım. yazdığımız fonkisyon ve alternatif olarak numpy nin mean metodu ile ortalama değeri hesaplamasını yapabilecek bir kod yazalım. hesaplamanın ne kadar sürede yapıldığını öğrenmek adına basit bir time yöntemi eklemeyi unutmayalım.
import numpy as np
import time
# Veri kümesinin ortalamasını bulan fonksiyon
def ortalama_bul(veri_kumesi):
toplam = sum(veri_kumesi)
eleman_sayisi = len(veri_kumesi)
ortalama = toplam / eleman_sayisi
return ortalama
# veri kümesi oluştur
veri_kumesi = np.random.rand(10000)
# numpy ile ortalama bulma
np_baslangic_zamani = time.time()
np_ortalama = np.mean(veri_kumesi)
np_bitis_zamani = time.time()
print(f"Numpy ile Ortalama hesaplama süresi: {np_bitis_zamani - np_baslangic_zamani} saniye")
print(f"Numpy ile Veri kümesinin ortalaması: {np_ortalama}")
# ortalama_bul fonksiyonunu kullanarak ortalama bulma
fonk_baslangic_zamani = time.time()
fonk_ortalama = ortalama_bul(veri_kumesi)
fonk_bitis_zamani = time.time()
print(f"Fonksiyon Ortalama hesaplama süresi: {fonk_bitis_zamani - fonk_baslangic_zamani} saniye")
print(f"Fonksiyon ile Veri kümesinin ortalaması: {fonk_ortalama}")
yukarıdaki kodda 10.000 adet veri için ortalama hesapları yapılmaktadır. kodu çalıştırdığımda elde ettiğim sonuç aşagıdaki gibidir.
Numpy ile Ortalama hesaplama süresi: 0.0 saniye
Numpy ile Veri kümesinin ortalaması: 0.5017341979294518
Fonksiyon Ortalama hesaplama süresi: 0.0 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.5017341979294502
veri boytunu katlayarak sonuçları kıyaslayalım. 100.000 değer için.
Numpy ile Ortalama hesaplama süresi: 0.0 saniye
Numpy ile Veri kümesinin ortalaması: 0.5008137222243555
Fonksiyon Ortalama hesaplama süresi: 0.0 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.5008137222243564
1.000.000 değer için
Numpy ile Ortalama hesaplama süresi: 0.0 saniye
Numpy ile Veri kümesinin ortalaması: 0.5000936635960163
Fonksiyon Ortalama hesaplama süresi: 0.046967267990112305 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.5000936635960234
hesaplamalarda ufak farklar görülmeye başladı. 10.000.000 için
Numpy ile Ortalama hesaplama süresi: 0.014102935791015625 saniye
Numpy ile Veri kümesinin ortalaması: 0.5002303952512933
Fonksiyon Ortalama hesaplama süresi: 0.5047390460968018 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.5002303952512889
aradaki fark artıyor. verimizi arttırmaya devam. 100.000.000 için
Numpy ile Ortalama hesaplama süresi: 0.09502911567687988 saniye
Numpy ile Veri kümesinin ortalaması: 0.49998983843975686
Fonksiyon Ortalama hesaplama süresi: 5.2369115352630615 saniye
Fonksiyon ile Veri kümesinin ortalaması: 0.4999898384397282
olarak bir çıktı elde ediyoruz. artık hesaplama süresini hissetmeye başladık. durmak yok veriyi büyütmeye devam
Traceback (most recent call last):
File "D:\python\ortalama.py", line 13, in <module>
veri_kumesi = np.random.rand(1000000000)
File "numpy\\random\\mtrand.pyx", line 1218, in numpy.random.mtrand.RandomState.rand
File "numpy\\random\\mtrand.pyx", line 436, in numpy.random.mtrand.RandomState.random_sample
File "_common.pyx", line 307, in numpy.random._common.double_fill
numpy.core._exceptions._ArrayMemoryError: Unable to allocate 7.45 GiB for an array with shape (1000000000,) and data type float64
1 Milyar için hesaplama yapmak istediğimde ise numpy için kırılma noktasına gelmiş olduğumuz görüyoruz. numpy ile devam etmek istiyorsak veri kümesini bölerek işlem yapmalıyız. buna uygun basit bir kod yazalım.
import numpy as np
import time
# Veri kümesinin boyutu ve parça boyutu
veri_boyutu = 1000000000
parca_boyutu = 100000
# Ortalamaları saklamak için bir liste oluştur
ortalama_listesi = []
np_baslangic_zamani = time.time()
# Veri kümesini parçalara böl ve her parçanın ortalamasını hesapla
for _ in range(veri_boyutu // parca_boyutu):
veri_kumesi = np.random.rand(parca_boyutu)
ortalama = np.mean(veri_kumesi)
ortalama_listesi.append(ortalama)
# Tüm parçaların ortalamasını hesapla
genel_ortalama = np.mean(ortalama_listesi)
np_bitis_zamani = time.time()
print(f"Veri kümesinin genel ortalaması: {genel_ortalama}")
print(f"Ortalama hesaplama süresi: {np_bitis_zamani - np_baslangic_zamani} saniye")
bu kod içinde parca_boyutu artııkça toplam hesaplama süresinin uzadığı görülmektedir.
işleri daha karmaşık hale getirmek istemiyorsak dask modulünü kullanmak farklı çözüm olacaktır.
import dask.array as da
import dask
import time
dask_baslangic_zamani = time.time()
# örnek veri kümesi oluştur
veri_kumesi = da.random.random(size=(1000000000,), chunks=1000000)
# Ortalama hesaplama
ortalama = da.mean(veri_kumesi)
# Dask hesaplamasını başlatma
with dask.config.set(scheduler='threads'):
sonuc = ortalama.compute()
dask_bitis_zamani = time.time()
# Hesaplanan ortalama değeri ekrana yazdırma
print(f"Veri kümesinin ortalaması: {sonuc}")
print(f"Dask ile Ortalama hesaplama süresi: {dask_bitis_zamani - dask_baslangic_zamani} saniye")
dask ile çalışırkenden chunks değeri hesaplama sürenizi eklieyecektir. 1 milyar değer için 100 bin değeri bende en optimal sonucu veriyor.
1 milyar veri için dask ve numpy de en optimal parametreler ile elde edilen sonuçlar aşagıdaki gibi çıkmakta…
dask
numpy
1 milyar veri
1 milyar veri
2.631504535675049 saniye
5.981382369995117 saniye
buradaki kodlar en optimal kodlar olmayabilir ve daha hızlı yöntemler oluşturulabilir. ancak bu haliyle kişisel bigisayarımda 1 milyar ve üzeri veriler için dask kullanmak çok daha mantıklı geliyor.
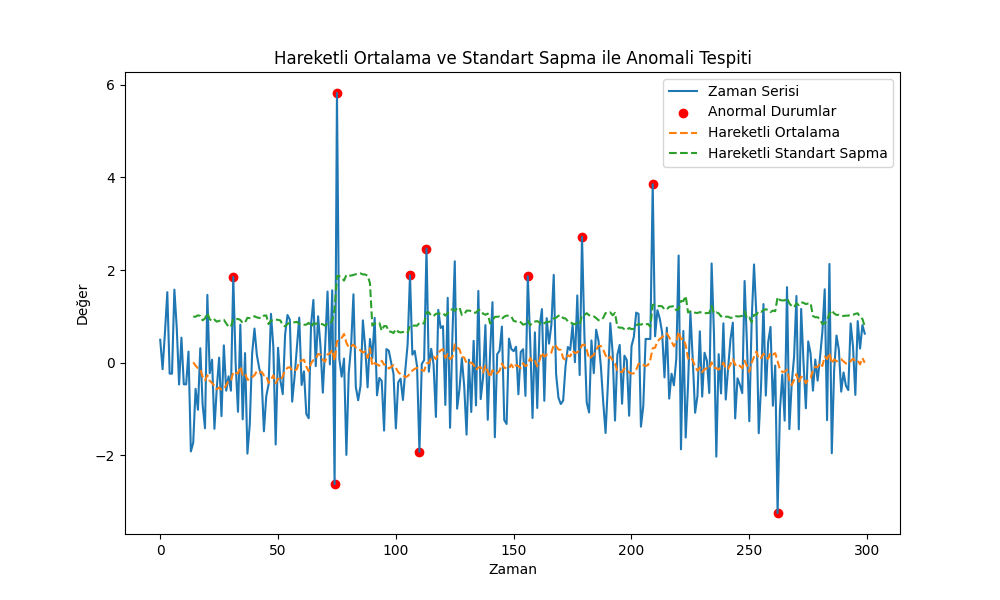
bir zaman serisinde anormal noktaların tespitinde kullanılabilecek yöntemlerden bir tanesi hareketli ortalama ve standart sapma kullanmaktadır. basit bir python uygulaması yapalım…
çıktıdan görüleceği gibi doğruluk oranı tüm uygulamalar için işe yaramayabilir. anomali tespiti giriş seviye uygulamalarda kullanılabilir.
google geliştiriciler için duet ai yi duyurdu. şu an için kullabilmeniz için google cloud bir hesabınız olması gerekiyor. cloud üzerinde bir proje oluşturdukten sonra bu proje üzerinden devam edebiliyorsunuz. google ın cloud hesapları konusunda güncellemeyi kaçırmısım anlaışanki yeni proje oluşumu sırasında proje sayısının 15 ile sınırlı olduğu yönünde bir uyarı mesajı ile karşılaşmak sürpriz oldu.
projeyi oluşturduktan sonra vscode ile hemen denemek istedim ancak kurulum başarılı olsada duet chat bir türlü çalışmadı. pycharm ile devam etme kararı sonrasında sorunsuz duet chat i çalıştırabildim. ilk test tabiki Türlçe testi oldu. şu an için Türkçe desteği yok.
Sorry, I can only respond to English questions right now. If you would like help in another language, please visit our documentation website or contact our Customer Care team.
aynı soruya duet ai nin ve github copilot un verdiğin cevaplar aşagıdaki gibi. her iki kodda çalışmamakta ve ikisinede çalışır şekilde düzelttiremedim. 🙂
testleri yapıp vscode u tekrar açıp uzantılardan kaldırmandan önce son kez denediğimde duet chat çalışmaya karar verdiği anlaşıldı.
github copilot
import multiprocessing
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n ** 0.5) + 1):
if n % i == 0:
return False
return True
def find_primes(start, end):
primes = []
for n in range(start, end):
if is_prime(n):
primes.append(n)
return primes
if __name__ == "__main__":
num_processors = multiprocessing.cpu_count()
pool = multiprocessing.Pool(num_processors)
chunks = [range(i, i + 100000) for i in range(0, end, 100000)]
tasks = []
for chunk in chunks:
tasks.append((chunk[0], chunk[-1]))
results = pool.map(find_primes, tasks)
primes = []
for result in results:
primes += result
print(primes)
github copilot
import math
import multiprocessing
def is_prime(n):
if n <= 1:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = math.isqrt(n)
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def find_primes(start, end):
primes = []
for n in range(start, end):
if is_prime(n):
primes.append(n)
return primes
def find_primes_multiprocessing(start, end, num_processes):
pool = multiprocessing.Pool(processes=num_processes)
chunk_size = (end - start) // num_processes
ranges = [(start + i*chunk_size, start + (i+1)*chunk_size) for i in range(num_processes)]
result = pool.starmap(find_primes, ranges)
pool.close()
pool.join()
primes = sum(result, [])
return primes
primes = find_primes_multiprocessing(0, 100000, 4)
print(primes)
pythonda çalışmanın dezavantajlarından bir tanesi yazdığınız kodları işletim sisteminde çalıştırabilir dosya haline getirme konusudur. çok fazla tercih etmesemde bazen gerekebiliyor.. bu noktada birden fazla seçenek mevcut ancak genel olarak en popüler olanları kullanmak daha fazla kütüphane v.b. konuda soun yaşamamanızı sağlıyor.
pyinstaller seçeneklerin en popüleri diye biliriz. tabiki ilk önce kurmamız gerekiyor.
pip install pyinstaller
kurulumu tamamladıktan sonra kullanımı oldukça kolay. komut yorumluyacısında ihtiyacımız olan parametreleri girerek exe dosyasını oluşturuyoruz.
pyinstaller --onefile dosyaadi.py
komut tamamlandığından python dosyasının bulunduğu klasör içine dist ve build isimli iki yeni klasör oluştuğunu göreceksiniz. dist klasöründen exe dosyanız build klasöründen ise exe oluşturma sürecinde kullanılan dosyalar yer almaktadır.
yukarıdaki komut yapısını kullandığınızda yazdığınız kod ihtiyaç duyulan tüm sistem dosyalarını tek bir dosya içine dahil etmektedir. bu nedenden dolayı dist klasöründeki exe dosyasına incelediğinizde yazdığımız üç beş satır koda karşı oldukça büyük boyutlu olduğunuz göreceksiniz.
eğer gui şeklinde bir uygulama yaptızsanız programı çalıştırdığınız ilave bir console pencesi açılmaması adına noconsole parametresinin eklenmesi gerekmektedir.
pyinstaller --onefile --noconsole dosyaadi.py
oluşturlan dosyanın iconunu değiştirme gibi bir çok seçenek için https://pyinstaller.org/ adresi incelemenizi öneririm.